Written by Kaarle Ritvanen
October 14, 2012
This document proposes a new architecture for the Alpine Configuration Framework (ACF). It addresses the following problems in the current architecture:
The proposed architecture has the following properties:
The new architecture would enable an incremental development model, where simple but fairly usable modules can be implemented with very little effort. More sophistication may be gradually added, utilizing powerful but generic building blocks.
The configuration data model is a single tree structure containing the configuration data of all modules. A non-leaf node of the tree can be a model instance or a collection. A model instance describes the properties of some entity and has a pre-defined structure, defined by a model, which is reflected on its subordinates. A collection is either a list or dictionary. Leaf nodes can be empty collections, values of primitive types (i.e. numbers, strings, and boolean values), or references to other nodes of the tree.
Each node in the configuration tree has a unique canonical path name that indicates the node's absolute position in the tree. In addition, a node can have multiple relative and/or indirect path names, where its position is determined relative to another node and/or with the help of one or more references (cf. with symbolic links).
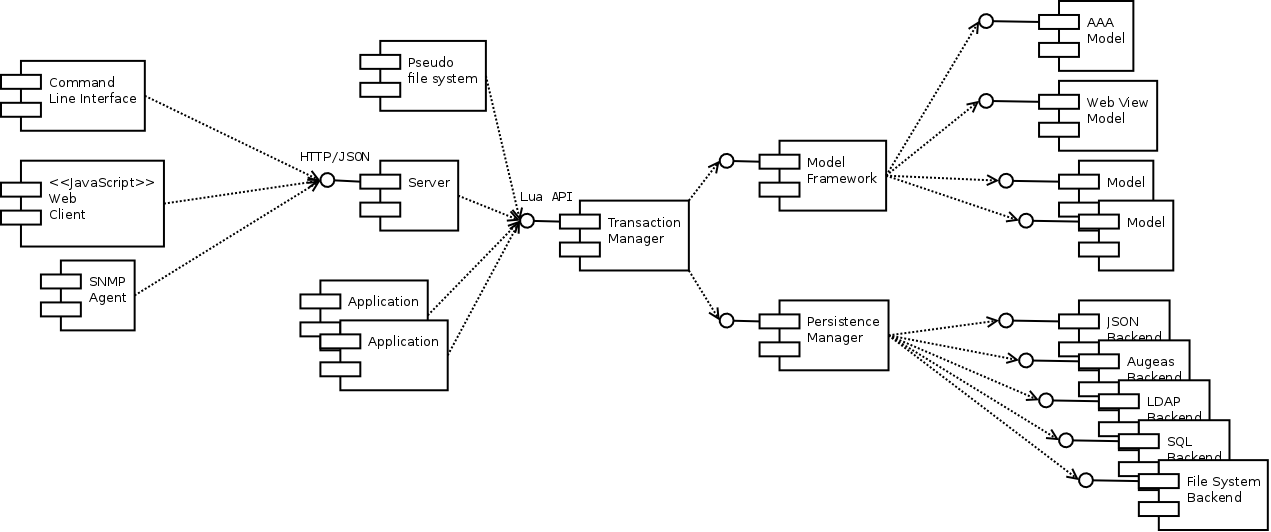
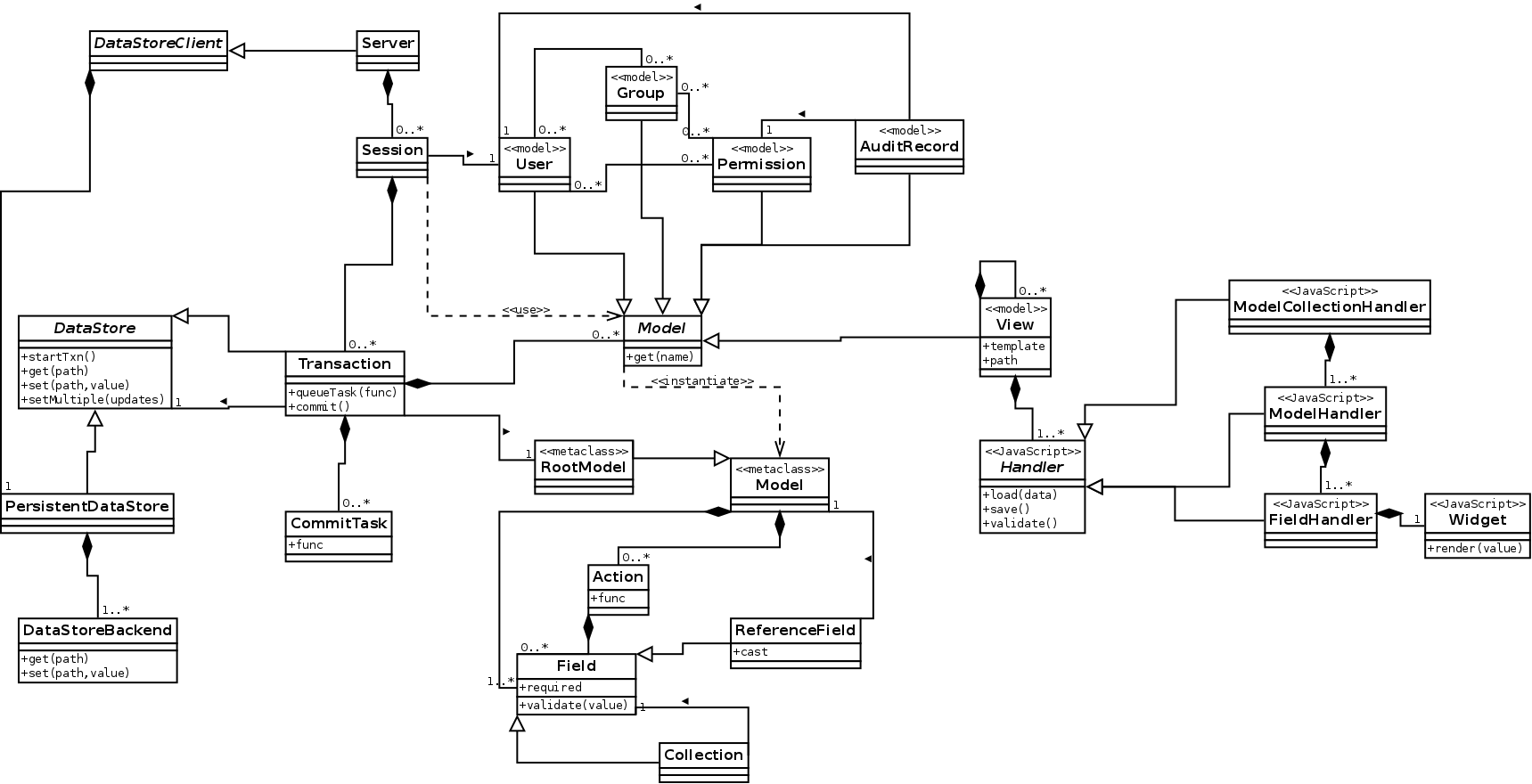
The proposed architecture is illustrated by the following advisory component and class diagrams. These diagrams are provided only as reference. The implementation may differ from them in details.
The most crucial component in the system is the Model Framework (MF). This component consists of module-specific models and a library for building such models. A model definition consists of data fields and methods applicable to the instances of the model. The library makes it possible to define models as Lua tables, the values of which describe the fields and methods.
A model field defines a named attribute that can be assigned to an instace of the model. In the configuration tree, the attributes map to the subordinates of the model instance node. The field type defines the acceptable values for the attribute. The library provides field types for the primitive types, collections, references, and model instances. Field types may allow defining additional constraints, such as the maximum length, the scope of reference, the type of referenced object, the type of collection members, or whether the value is mandatory. The library shall support field type inheritance, such that modules may define field types with additional constraints (e.g. a field type for IP addresses). A field may be defined as virtual, in which case the value is determined by a model function rather than being retrieved e.g. from a file or database. One of the model fields may be defined as the key, the value of which is used as the key when the instance is stored into a dictionary.
A model method is a Lua function that performs some query or function specific to the model. A model action is a special case of a model method. An action is visible at the user interface level and may be invoked directly by a user with appropriate permissions. An action definition may contain a list of arguments, defined in terms of field types.
In order to simplify model implementation as much as possible, the library makes extensive use of Lua metatables. This technique allows hiding most of the complexity on the library side. The library shall also support model inheritance to encourage modularity.
MF does not deal with storing or retrieving data from files or databases. These tasks are the resposibility of the Persistence Management (PM) component. PM has a plug-in architecture and supports at least JSON files, Augeas lenses, and direct mapping to the file system. Direct mapping may be useful with pseudo–file systems such as /proc. Plug-ins for SQL databases and LDAP directories may also be implemented. Each plug-in is responsible for translating between the backing store and a single subtree in the data model (cf. with file system and its mount point).
The subtrees managed by PM plug-ins are not directly visible to users. Relevant parts of these subtrees are referenced by models to make them visible. In connection with these (virtual) references, the models also specify which model shall be used to interpret the raw data in the referenced subtrees. A model can aggregate data from multiple backing stores, thereby constructing logical views combining e.g. actual configuration data and run-time data from /proc.
The root configuration object is an instance of the root model. This instance displays the module-specific main objects as its subordinates. MF provides a registration mechanism for module-specific models.
The Transaction Manager (TM) is a component that mediates between PM, MF, and user requests. TM implements transactional behavior for model instances, enforcing ACID semantics for all requests. TM ensures that only consistent sets of configuration tree updates get submitted from MF to PM by temporarily storing the updates for open transactions. TM intercepts MF's queries to the PM and modifies the response according to the stored updates. On commit, the updates are propagated to PM. TM also supports nested transactions, in which case committing the inner transaction propagates the updates to the outer transaction instead of PM.
The transaction implementation ensures the ACID semantics by recording at which time it was started. When retrieving values from the back-end, i.e. PM or outer transaction, it verifies that the value has not been modified after the transaction was started. The timestamps are re-checked on commit phase for each retrieved value. If any value was modified during the transaction in the back-end, transaction is aborted. The back-end is responsible for providing an atomic operation for timestamp comparison and updating for multiple objects, as well as maintaining the timestamps for each value.
Each back-end is responsible for maintaining the value modification timestamps. The implementation method and level of granularity depends on the back-end. The timestamps may be stored persistently e.g. per value or file. Memory-based bookkeeping may be used to increase the granularity at run-time if value-specific timestamps are not available.
TM provides a Lua library interface that exposes transaction controls and functions for accessing the configuration tree in the context of a transaction. The tree nodes returned by the library are of primitive Lua types, model instance objects, or collection objects.
Each model instance object implemented by MF is bound to an open transaction. By themselves, model instance objects are stateless. When its attributes are changed or its methods query other nodes of the configuration tree, the instance object interacts with TM as described above. Attribute changes and method invocation may take place due to direct user request or indirectly by other model instance methods. Attribute change triggers validation of the new value according to the field type before the update is sent to TM. From API point of view, attributes shall appear as normal table values and methods (and actions) as functions accessible with the colon notation. This makes interacting with the instance objects convenient, and can be achieved by clever use of metatables.
The collection objects returned by the library can be operated like normal Lua tables used as lists or dictionaries. In reality, the collection objects are stateless and interact with TM as model instances do. This is achieved by metatable tricks. In order to support big collections (possibly backed by an SQL database), it might be necessary to provide additional functions for e.g. searching and slicing. Implementing these may also have an impact on TM's interfaces with MF and PM.
In addition to sending data updates to the transaction, model instaces may insert Lua functions to the transaction's commit task queue. These functions get invoked immediately after flushing the updates to PM. Typically, these functions signal the relevant services to reload their configuration from files.
The server component is a daemon running with superuser permissions. It implements a REST protocol for accessing the configuration data, based on HTTP transport and JSON serialization of messages. The various user interfaces connect to the server using this protocol. The server also implements AAA functionality, which involves authenticating the users of the REST interface, and providing filtered views of the configuration tree according to the users' permission. The server also enforces permissions on administrative actions, i.e. updates on data and invocations of model instance actions. An audit trail of administrative actions is maintained. The AAA function uses MF to model the users, groups, permissions, and audit trail. On PM side, users and groups may be stored in an LDAP directory. At protocol level, HTTP's (digest) authentication feature can be used to collect client credentials. From semantic point of view, the REST interface is a superset of TM's API.
The proposed architecture supports multiple user interfaces, including Command Line Interface (CLI) and web interface. Also an SNMP interface is envisioned for centralized management and monitoring. The CLI will be a Cisco IOS–style shell. The structure of the CLI and SNMP interfaces is analogous to that of the configuration tree. The CLI must be aware of the MF field types in order to properly implement auto-completion. This function also requires that some model metadata can be queried via the REST interface.
The web interface, on one hand, can also be generated automatically based on the models and configuration tree structure. On the other hand, sometimes this can result in suboptimal usability, so module-specific customization must be allowed.
In addition to the REST interface, the server's HTTP implementation supports serving static content related to the web interface. Such content should be served only for authenticated users. Otherwise an attacker might easily collect some information on installed modules and possibly their versions.
Most of the contemporary web applications are implemented using server-side templating engines, where the server generates dynamic HTML pages and receives user feedback via CGI forms. In the proposed architecture, the web user interface is a client-side JavaScript program which interfaces with the server solely via the JSON-based REST API, i.e. a single-page application. All dynamic HTML is generated on client side using a JavaScript templating system, such as JSON Template or Eco, and injected into the browser's DOM tree. Consequently, the module-specific web interface customization code must also be written in JavaScript. The HTML templates and the JavaScript client with its module-specific extensions are served as static content by the server (using HTTP). The full client-side approach eliminates all possible HTML-related security vulnerabilities, which supports Alpine Linux's value proposition as a security-oriented distribution.
The main functionality of the JavaScript client is related to displaying views. A view is a dynamic HTML page that shows some data from the configuration tree and allows the user to modify it as per his permissions. A view is uniquely identified by a path name, which typically corresponds to the path of the configuration subtree to be shown. From module developer's point of view, a view consists of a HTML template, template-specific handlers (JavaScript code), and a configuration subtree containing the relevant data.
In order to display a view, the client performs a server lookup that maps the view identifier to a triplet of template name, list of handler names, and configuration tree path. This mapping can be shown inlined in the configation tree and can be customized by modules. The client obtains the template, handlers, and the desired configuration data from the server. The template and handlers can be cached because they are static data from server's point of view. The client then passes the configuration data to the handler, which produces a data structure populated with the data and model-specific metadata. Using this structure as input, the template is then rendered to HTML content to be shown in the browser.
When the user wishes to save modified data, the client invokes the handler to extract the relevant information from the DOM tree. This information is then converted to an appropriate server request. While displaying a view containing editable fields, the client keeps the transaction open and uses the same transaction to modify the data, protecting against concurrent changes by other user sessions.
Before sending the request to the server, the handler can perform some validation on the modified data. In any case, the validity is finally ensured by MF on server side, but client-side validation can be used for improving user experience.
A view may contain hyperlinks to other views. A view may also employ multiple handlers, in which case their outputs are combined before template rendering and server writeback. This is useful when objects of several types are shown in a single view.
In order to facilitate implementation of views, extensible default templates and handlers are provided. Examples of default templates:
Default handlers are provided to translate fields, model instances, and collections thereof to data structures suitable for template rendering. These are called field, model, and model collection handlers, respectively, and they are JavaScript objects which can be used as prototypes for customized handlers. As there are dependencies between the JavaScript extension files, the main client implements a loading mechanism ensuring that all relevant files are loaded from the server. The loader implementation may be based on an existing library, such as RequireJS.
A model collection handler delegates instance-specific tasks, including validation, to a model handler. A model handler delegates field-specific tasks to a field handler. A field handler delegates the rendering of HTML input, select, or textarea elements to a widget object. The widget object as well as field handler's subtype are by default selected based on the field type, but modules may use custom widgets and handlers to improve user experience. In absence of any module-specific customization, the automatically generated web interface views are produced using default templates and handlers.
A more lightweight customization method is to implement a special-purpose model that aggregates the desired configuration data to a subtree that is understood as such by a default handler. With this method, the possibilities are naturally limited by the capabilities of the selected handler.
There are some useful libraries on which the implementation of views and the REST client can be based. One such library is Backbone.js.
The visual layout of the web user interface can resemble that of the current solution. The module names shown on the left-side menu correspond to the first component in the view path. The tabs shown above the form could by default correspond to the second component.
There is room for improvement in the layout too. It would be good if the button for saving the configuration (lbu commit) were visible in every view whenever there are any unsaved changes in the configuration. The user could even enable automatic saving on commit (as a user-specific preference).
There should also be a place for displaying model-originating messages to the user, e.g. instructing the user to manually restart some services. Such messaging may be implemented e.g. by passing the messages via a collection in the configuration tree.
Sometimes it makes sense to update the view dynamically so that the user can observe the system's state changes in real time. An example could be a view displaying the contents of a log file. Achieving optimal user experience and use of network resources may require persistent HTTP connections, update notifications, and incremental updates. These features would require specific support in the server, TM, and MF components and their interfaces.
Some commit tasks and model actions could take a long time to complete. Such actions might be related to e.g. software updates. Ideally, a progress indicator would be displayed to the user while such action is ongoing. Also this feature would require support in the server, TM, and MF. There should be a means for the commit tasks and model actions to indicate their level of completion that could be communicated to the client.
Naturally, also the CLI could show informational messages, progress indicators, and visual alerts about unsaved changes.
In addition to the server component, there may be other processes interfacing with TM. For example, there might be a process that implements a user-space file system providing read-only access to the configuration tree. Some applications, such as Alpine Wall, could outsource configuration data validation to the library. An unprivileged process will naturally have only limited access to the tree. If any process other than the server is allowed to commit changes to the configuration, this must be taken into account by locking and timestamp functions of the PM plug-ins.
Albeit being somewhat complex, the proposed architecture is supposed to significantly increase the productivity of module developers. The architecture advocates an incremental development model, where each phase increases the sophistication level of the user interfaces.
The first implementation phase of a module typically includes so called expert mode, which allows the user to directly edit one or more configuration files in the web user interface. In the proposed framework, this is a matter of writing a few lines of simple declarations.
If an Augeas lens exists for the said configuration file, and this is made known to the framework by adding a few more lines of declarations, a CLI automatically becomes available for viewing and editing the file, as Augeas will translate the contents to a structure of strings and collections. This semantic awareness will also be reflected in the web user interface. Basic HTML forms are automatically generated to add convenience for non-expert users.
If the data related to the module is stored in an SQL database rather than files, the information available in the schema is mapped to the MF's concepts. This typically enables higher semantic awareness than with Augeas-backed data, since SQL schemas are strongly typed and employ concepts like foreign keys. Different column types, including foreign keys, map nicely to MF primitive fields and references.
In order to bring the semantic awareness to the highest possible level, the module developer must explicitly specify the model. This enables the best possible usability with CLI, but can be postponed to a later phase of module development.
Specifying the model improves the user experience also in the web interface. For example, Augeas does not natively distinguish between enumerations, references, and other strings. Enumerations and references would be better displayed e.g. as combo boxes or radio button groups. In a later development phase, the module's usability can be further enhanced by client extensions.
Natanael Copa, Timo Teräs, and Nathan Angelacos have provided valuable input for this document.